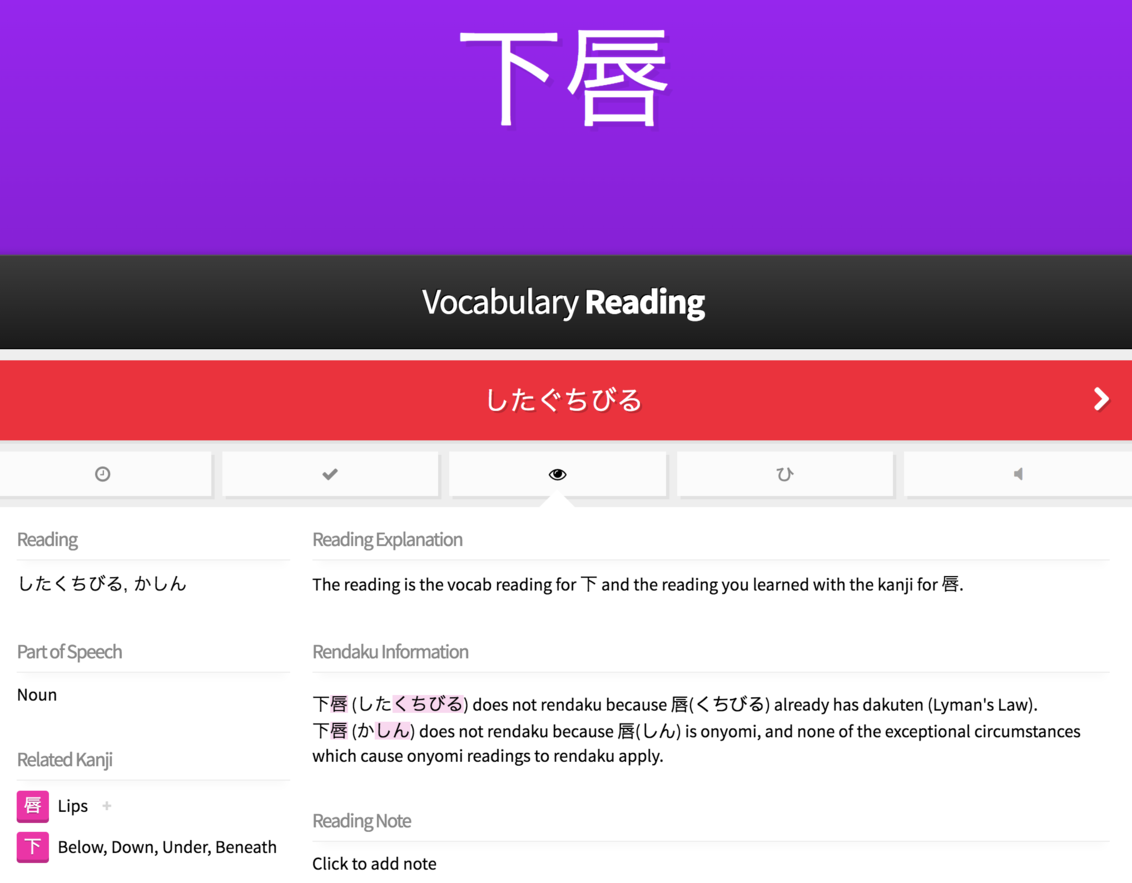
This script adds a “Rendaku Information” section to the lessons information for every vocab word, attempting to explain why it does or does not rendaku.
How to install
Get Tampermonkey (installation instructions in this thread).
Click on the installation link (Tampermonkey should auto-detect .user.js files)
Install the script after you check the security (at least see that script will only change the wanikani website, all @include should be related to WK).
The rendaku explanation generated by the userscript uses some simple rules, which are roughly inspired by the Tofugu article Rendaku: Why Hito-Bito isn’t Hito-Hito. The rules are (loosely):
Kunyomi readings usually do rendaku, unless…
this or subsequent characters already have dakuten (Lyman’s Law),
the preceding character is a particle or honorific prefix,
the kanji is one of a certain set which do not usually rendaku even when read as kunyomi.
Onyomi readings usually do not not rendaku, unless…
the reading starts with ‘h’ and follows ん, つ or ち,
the kanji has two onyomi readings and one is the rendaku’d version of the other
the kanji is one of a certain set which do usually rendaku, even though they are onyomi.
About 170 words don’t follow the above rules, in which case the userscript states what the closest rule is and flags the word as an exception. Hopefully more patterns can be identified in the future to reduce the number of exceptions.
Acknowlegements
The part of the script for injecting extra sections into the lessons is directly borrowed from the awesome Semantic-Phonetic Composition userscript - thanks acm2010!
Please report bugs and suggest improvements. This is my first userscript so please bear with me if it totally doesn’t work - I’ll try to fix it! I will hopefully continue to enhance the data and the way it is presented in the near future. There are about 3000 explanation messages generated by the script and I have not read them all(!) so if you see anything that needs improvement, don’t be too surprised and let me know.
Thanks for the script, I will try it when I get home!
One thing I noted directly: “魔法 does not rendaku because 法(ほう) is onyomi” doesn’t really give a reason, 法 in 文法 also uses the onyomi but reads ぽう.
Is this just an explanation that a rendaku will use something other than ほう?
It would be better to give some message like “X never uses rendaku (onyomi no rendaku rule applies)”, or “法 sometimes uses rendaku, sometimes it doesn’t (certain set rule)”.
“魔法 does not rendaku because 法(ほう) is onyomi” is supposed to be shorthand for “魔法 does not rendaku because 法(ほう) is onyomi, and onyomi readings usually don’t rendaku, and none of the exceptional circumstances which will cause onyomi readings to rendaku apply”. Or something like that. My thought was that I wanted to keep the presentation of the information concise, so that rather than giving a complete lesson on rendaku rules on each page, you could see at a glance the most relevant “reason”, and hence quickly figure out where this specific word fits in to the bigger picture.
For each word, generally the highest level relevant rule is presented. The more exceptional rules, and exceptions, appear on the words which exhibit them: e.g. for the 文法 example it currently says:
(I see that ‘rendaku to “p”’ not really an accurate way to express this as Leebo points out so the wording would benefit from some improvement).
And then there are some cases which the script currently does not attempt to explain at all. I still think it is useful even just to see these flagged as exceptions because this should help you remember which cases follow the rules and which don’t. Most words actually do follow somewhat consistent rules, which I had never previously been able to identify.
Ok, so I’m just trying to explain the meaning and motivation of the current messages, but your point makes sense (that the wording in my original example is incomplete and thus potentially misleading or confusing). Maybe it would be better to say:
“魔法 does not rendaku because 法(ほう) is onyomi, and none of the exceptional circumstances which cause onyomi readings to rendaku apply.” Or something like that. Possibly with “exceptional circumstances” being a link to expand the page to show the full rules, including listing the exceptional circumstances.
The sentences output by the script are currently all generated programatically, so it is slightly awkward to make sure they still read like English when stitched together, hence the exact choices of wording is slightly constrained, but that can be fixed with more effort.
To anyone using this script, or who might use the script… I have made (and am continuing to make) updates. Nothing is massively different, but I think lots of the wording is significantly improved and there have been some enhancements to the rendaku rules which are applied. I’m not sure if tampermonkey will pull in the updates automatically but I’m pretty sure that if you click on the installation link again it will update for you. It’s currently at revision “0.2001”.
Basically every time I get rendaku wrong in my reviews (see my latest review fail in the revised screenshot in the first post in the thread) I look at the “Rendaku Information” and fairly often I think hmm… this could be worded better, or perhaps there’s a new rule to be applied here. Then I stop doing reviews and start updating the script. Hence expect more ongoing script updates. Hopefully my improved rendaku accuracy will offset the scripting time…!
This script is SO useful!
I was continuously messing up with kinjo/benjo/etc until I finally an all-in-one explanation:
Rendaku Information
近所 (きんじょ) does rendaku because although 所(しょ) is onyomi, 近所 is one of the four places in WaniKani (your friendly neighborhood/toilet/rest area/gas station) where 所(しょ) rendakus.
Would it be too much hassle to put this under the rendaku info? I feel like it’s really crucial info. Maybe it can be colored gray so it’s not so obtrusive? And make it toggle-able or something for the minimalists? Thankies
Still waiting to get to my own vocab lessons but I had one person check a lesson and the rendaku information looked okay, so there might be more variables involved here. Could anyone who is seeing this post a screen shot? Thanks!
The issue turns out to have been caused by both your script and another script declaring a global variable named DATA. Would it be possible to scope things locally in your script? The other one appears unmaintained. Sorry for not realizing it was a script conflict initially.
Thanks for (hopefully) tracking it down. I have released a version 0.2003 where I renamed that global variable to WK_RENDAKU_INFO_DATA. I’m nervous to make any other changes since I haven’t looked at the code for 2 years. Let me know if it works!