I’ve written in my study log about various tools I’ve developed to track my progress in learning vocabulary appearing in the manga I read.
The culmination is:
Purpose
Sites such as jpdb and Koohi do a good job at providing frequency information and word lists for novels and anime, but I’m unaware of anything for manga.
Manga Kotoba is designed for finding how readable a manga will be and which words you should learn next based on your own personal vocabulary.
Features
- View series-level and volume-level vocabulary by frequency.
- Track known vocabulary.
- See your progress in learning the total vocabulary from a series and its volumes.
- See the number of sentences you can read without looking up vocabulary.
- Export any frequency list, which is useful for importing into JPDB.
- Frequency lists for over 8,500 volumes across over 3,280 manga series.
Screenshots
Browse Series List
Designed to discover material to read, the “Browse” page lists all available manga sorted by the percentage of words you know in a series.

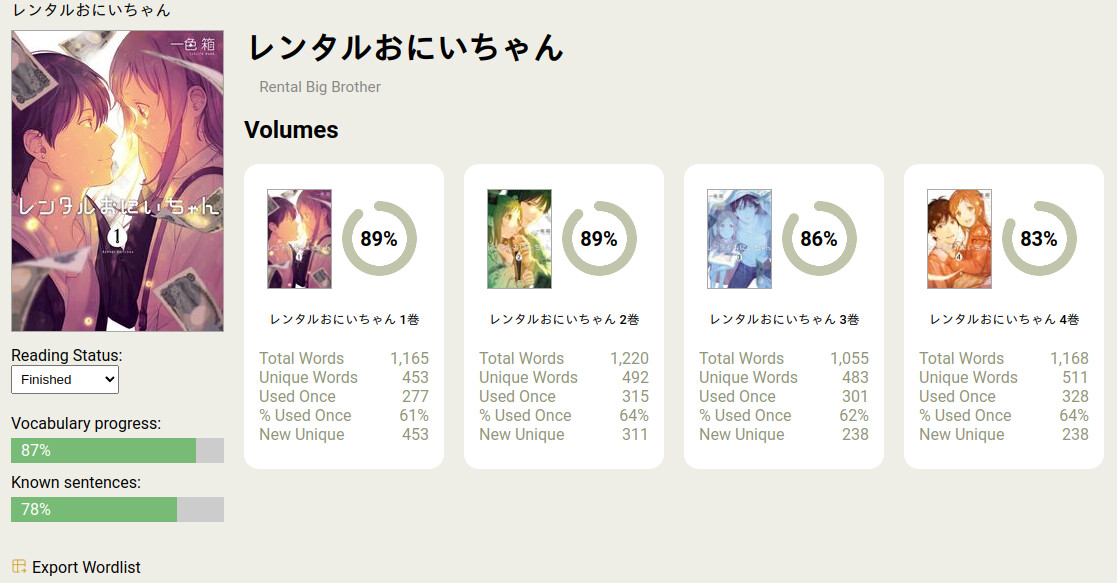
Series Page
The series page lets you select your reading status for a series and shows your vocabulary progression for the series and all (available) volumes.
Note: This screenshot shows an in-development view of the volumes. Currently, the only available volume view is a table-based view, which will remain as an option once this layout goes live. I just need to work the series vocabulary stats and link section into it.
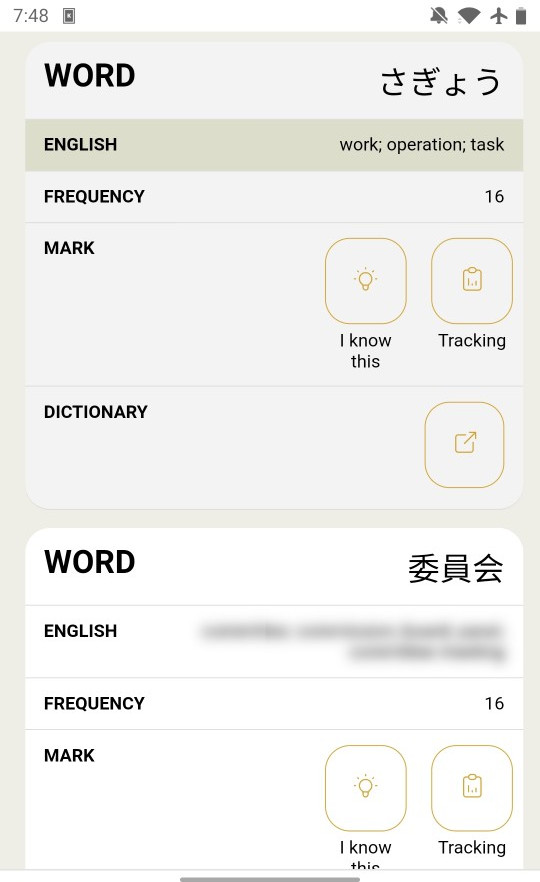
Vocabulary Frequency List
Desktop:
Mobile:
Each series and volume has a vocabulary list sorted by frequency.


User Series List
From the dashboard, you can access a list of all the series you have assigned a status to, and your progress stats. (This page is currently called “My Series”, but I’m still debating whether to go the “Your Series” route.)

Recommended Words List
From the dashboard, you can access a frequency list for all series you’ve marked as reading or a few related statuses. This lets you decide which words to learn from single frequency list combined from everything you’re reading.

Known Words List
You can view your known words list from the dashboard. If you accidentally mark something as known, you can unmark it from here.

Import Known Words
If you have a list of known words, you can import them here.
Note: Until I add pagination to the import review page, it’s best not to add more than 200 words at a time. Also, it’s best to avoid hiragana-only words as they may match on many different kanji words.
Note: At the moment, marking words as known from this page doesn’t work. Getting it working is on my short-term to-do list.

Limitations
- Small (but growing) selection of manga.
- It’s mostly sourced from time-limited full-volume free previews and manga I’ve purchased.
- The site still is in early development. Things may occasionally break or be shuffled around, and test pages/sections will come and go from time to time.
- Limited mobile device support.
- The most important parts are usable, but I still have more work to do.
- No password reset feature yet.
Requesting a Series
I can add a series by request, provided you can complete these steps:
-
Purchase a digital copy of the volumes from the series.
-
Remove DRM and unzip contents.
-
Install Mokuro and run it on the volume folder that contains the manga page images.
-
Optional: Include a text file listing character names. This is used to remove character names.
-
Optional: Include a text file listing file names of pages that do not include content (such as cover image, table of contents, あとがき, copyright page). This is used to remove unnecessary vocabulary.
-
Compress Mokuro’s output _ocr folder and any optional files into a zip file.
- Do not include the images folder!
-
Share the zip file with me on Google Drive, or else send me a message on Discord at ChristopherFritz#5813 with a link to the zip file.
Note: I don’t know Discord very well, and I’m only on it a few times a month. I’m not certain if I can actually receive messages from random people. But leave a comment in this thread, and we can coordinate.