Yep, go to the GitHub link in this thread’s first post, click Code, and you’ll find a link to the TestFlight beta in the README
1 Like
It seems like there has been an update today. does anyone else feel like the change from the normal keyboard to flick-keyboard is way slower now?
1 Like
It looks like the update also differentiates between “current level” (the level you recently guru’ed radicals and kanji for / the previous level)(in my case lvl 11) and “next level” (the level you are currently learning)(lvl 12) now.
With this update, the filter that lets you review “current level” items first is actually filtering for the items from the level you already finished instead of the ones you just learned and need to get to guru. Is there a way to work around this? I mostly use tsurukame to work on level-up items as they appear and then work on the older review when I get home, so being able to filter for the level-up radicals and kanji again would be great.

That’s actually just a visual thing. It doesn’t change anything else and you’re welcome to turn this setting off if it bothers you (Settings → Radicals, Kanji & Vocabulary → Keep current level graph). Normal policy would be that this should have defaulted to false to maintain consistency between versions, but this was unfortunately not caught before release.
Are you sure you have items to review for your real level N? The current level first setting has always been level N items if present, then level N - 1 items if present, and so on.
“Next level up review” shows as 2h in your photo, so you definitely didn’t have any whenever you took the screenshot.
1 Like
I don’t mind the previous level charts being there, they’re certainly helpful to make sure I finish the previous level before level-ing up.
I don’t have any current level reviews right now, but when i first started level 12 and had only completed lessons for the radicals and a few kanji, 4 hours later when I went to review I was getting vocab questions instead of the radicals I had just learned. I can check again when I have to review some level 12 kanji tonight.
Good idea. You can also play with turning on/off the setting (followed by a refresh for good measure) – bonus points for decreasing batch size to 3 – to determine if the setting is a workaround or not.
I’d suggest reporting this to GitHub tonight along with whether the setting is a workaround once you have this information.
1 Like
I think the issue was that I have some vocab items in my reviews that have been moved (either before or after I reset) to higher levels so they appeared before my level 12 items. 外れる was the first item in my queue even after refreshing and it looks like it’s a level 19 item now.
Thanks for taking the time to help me out!
The current and next level chart is great ![]()
2 Likes
Continuing the discussion from Level 60 ![]() and my study habits:
and my study habits:
Sorry for the long winded post, but I’m curious why tsurukame might affect accuracy stats on wkstats. This post is mostly to write my understanding down somewhere.
I suspect @wiersm might be right that tsurukame somehow causes artificially high “accuracy” reporting from wkstats.
(Hopefully, I’m posting this in the Tsurukame thread as intended. I’m unfamiliar with tsurukame and wondering if this is a known issue).
Here are my stats for comparison:

@wiersm: I never used tsurukame. Since you said you used it often, would you mind posting your wkstats accuracy for comparison?
@rfindley: please confirm my assumption that wkstats calculates this table solely from the review_statistics object for each subject.
Gory background re: question vs. review accuracy
Note that Total “Reviews” in the wkstats output is a slight misnomer.
Technically, wkstats appears to sum Correct and Incorrect answers and report it as “Total Reviews”.
To be pedantic, I think this would be better labeled “Total Answers” (or Total Quizzes/Questions). It’s a subtle distinction, but you might answer incorrectly more than once for a given subject within a single review session.
To my mind, at least, only items/subjects are reviewed. Meanings and readings are individually quizzed and answered for each subject, but, ignoring radicals, you must provide two correct answers to complete a review for a given subject.
WKstats appears to report what I call “question accuracy”:
total_correct = reading_correct + meaning_correct;
total_incorrect = reading_incorrect + meaning_incorrect;
total_answers = total_correct + total_incorrect;
question_accuracy = (total_correct / total_answers) * 100;
The API tracks correct/incorrect counts for an individual subject in the Review Statistics data structure. I believe this structure is updated whenever an individual Review record is created for a subject.
Ignoring scripts and tusurukame, the official web app only creates a Review record whenever both the reading and meaning components for a subject are eventually answered correctly.
So whenever all components of a subject are answered correctly, wanikani adds exactly one to reading_correct and meaning_correct for that subject. It will also add zero or more to the incorrect counts for that subject (depending on how many times an incorrect answer was provided).
Thus, a pedantically precise count of Total Reviews isn’t simply the sum of all correct and incorrect answers, it’s:
total_reviews =
correct_radical_meaning
+ (correct_kanji_meaning + correct_kanji_reading) / 2
+ (correct_vocab_meaning + correct_vocab_reading) / 2
Item accuracy vs. question accuracy
The summary pages (that are soon going away) report item accuracy, the percentage of subjects that were reviewed with no incorrect answers for either reading or meaning. This is usually a smaller number than question accuracy.
For a given radical:
item_accuracy = (meaning_correct - meaning_incorrect)
/ (meaning_correct + meaning_incorrect)
* 100;
For kanji or vocabulary subject, the only absolutely accurate way to calculate item_accuracy is to walk through every individual Review record (which is extremely expensive since a user might have hundreds of thousands of reviews).
If you ignore repeated incorrect answers within a single session (which are hopefully fairly infrequent) it can be approximated for kanji/vocab items as:
item_accuracy = (meaning_correct + reading_correct
- meaning_incorrect - reading_incorrect)
/ total_reviews
* 100;
(This slightly _under_states the item accuracy, though, as it dings you for every incorrect answer within a session, not just the first.)
Questions
I know that tsurukame “batches” data and uploads it to the server periodically (I ran into this after discovering that review records for some users weren’t always in chronological order). I’ve no idea how or why that would affect accuracy stats, though.
For wkstats to be overstating question accuracy, it must somehow be under-reporting incorrect answers, or over-reporting correct answers. The former seems more likely.
One hypothesis: perhaps it never records more than one incorrect answer within a “session” (however it defines a session). Maybe it just marks a subject review as “incorrect” and doesn’t count all the incorrect meaning/reading replies?
Another hypothesis: how does it handle multiple reviews of the same subject (multiple sessions) between uploads via the API? Is it possible that affects things somehow?
Final hypothesis: @wiersm has the memory of an elephant and really does have 95%+ question accuracy.
1 Like
Yep, correct.
1 Like
Yes, this is a specific user-controlled option. Its review settings page has a toggle switch that allows users to “Minimize review penalty: Treat reviews answered incorrect multiple times as if answered incorrect once.”
3 Likes
Interesting!
Thanks for the reply. That explains it.
Apparently, I lied. I have used the app before at least a few times (I think I stopped doing any reviews on my phone, app or web, around level 7). Anyway, I have it on my phone.
It appears that this setting defaults to “on”? That’s kinda surprising. Especially since “reveal answer automatically” also defaults to on.
1 Like
Here are my accuracy stats according to wkstats:
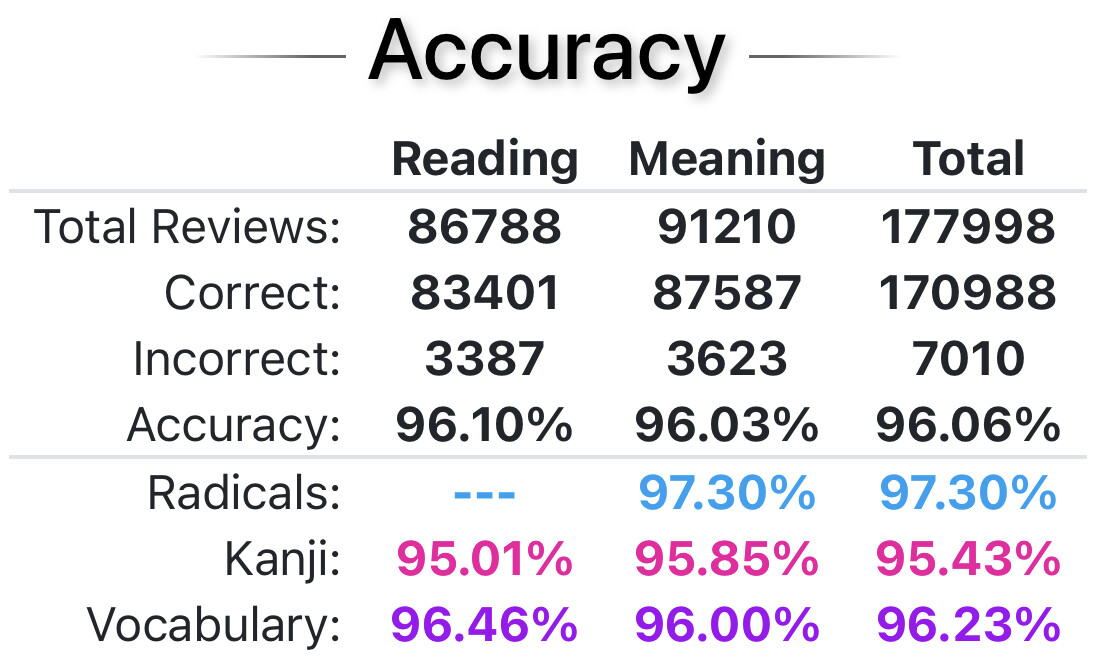
Now maybe I have a pretty good memory, but these stats seem quite excessive to me. They also don’t match what I see in Tsurukame because most of my review sessions seem to be between 80% to 90%. Occasionally I used to score 100% (when reviewing items I learned the same day, for example) but I don’t think that is enough to raise the statistics this much.
Ah yes, I did have this setting on the default for a long time because I didn’t know about it at first but I did switch it some time ago.
1 Like
The first thing that jumps out at me is that we started at roughly the same time, but I’ve recorded roughly double the number of answers that you have: 349,363 vs. 177,998.
That seems surprising, but not inconceivable. It’s not just an extremely low number of incorrect answers, the total count (correct + incorrect) also seems quite low.
It seems like a stretch to attribute this big a difference in our stats entirely to repeated incorrect answers. I’m not the sharpest knife in the drawer, so it’s entirely conceivable that your accuracy really was considerably better than mine, but double the number of questions is still a suprise.
I just did a review session of 4 subjects (8 reading/meaning questions) using tsurukame to learn how it behaves. I provided the incorrect “meaning” answer to two different subjects. Unsurprisingly, it correctly reported what I call the “question/answer accuracy” in the upper right of each review screen next to the thumbs-up icon (at the end: 2 repeated questions, 8 eventually correct answers out of 10 total questions = 80% question accuracy).
Confusingly, what I call “item/subject accuracy” tsurukame labels “Correct answers” on the Review Summary page: “50% (2/4)”. Note that 50% is a significantly smaller number than 80%, but both values are correct and are measuring roughly the same thing (how well one did in a session).
This sounds like I disapprove, and I don’t mean it that way at all, but I see that tsurukame apparently defaults to “Allow cheating (ignore typos and add synonyms)” as well as “Minimize review penalty”.
I suspect the huge difference in our stats can be attributed at least partially to both of these two settings, in addition to my likely poorer retention. My stats included repeated incorrect answers as well as every typo or user synonym I added after getting marked incorrect (where many of these might not have been recorded in your stats).
~96% question accuracy stats seems surprising, but plausible with mostly 80-90% item accuracy, especially if repeated incorrect answers were mostly unrecorded, and no typos or added synonyms were marked incorrect.
Example
Let’s say you and I both had a review session of 100 kanji/vocab items, and we both answered either the meaning or reading incorrectly for 8 of them. Let’s further say we both had 3 typos or added synonyms. There are 100 items, but 200 questions.
##Tsurukame case:
192 questions were answered correctly on first attempt, but 8 were repeated. So the question accuracy would be (192+8)/(200+8) = 96.15%. The item accuracy would be 92/100 = 92%.
The Wanikani web app (my stats) would record 11 incorrect answers, or a question accuracy of (189+11)/(200+11) = 94.78%. The item accuracy would be 89/100 = 89%. Both are appreciably lower than what tsurukame records.
The effect is independent of the number of items in a session. Missing one question for 16 different items in a 200 kanji/vocab session would still give 400/416 = 96.15% question accuracy, but only 184/200 = 92% item accuracy.
Tl;dr
The ~96% accuracy reported by wkstats is plausible based on the two default settings above. It’s also plausibly consistent with typical “item accuracy” in the upper 80% to 90% range during review sessions.
Still: literally double the number of questions recorded in my stats vs. yours came as a surprise.
1 Like
Thank you for the thorough sleuthing @Rrwrex ! ![]() So maybe the numbers do add up and I just got confused because they are presented differently. The typos and synonyms cheating is definitely one of the reasons why I like the app, so that is certainly a factor in my numbers.
So maybe the numbers do add up and I just got confused because they are presented differently. The typos and synonyms cheating is definitely one of the reasons why I like the app, so that is certainly a factor in my numbers.
1 Like
Has anyone else been having the problem that the keyboard disappears when it switches between EN and JP keyboards? I don’t remember it doing that before the recent update, and I find it jarring and rather uncomfortable. Before, I’m pretty sure it switched smoothly like when I switch it manually (which I’m doing now; I stopped using TK after the update, but now with WK [hopefully only temporarily] breaking scripts, I redownloaded it to see if it was working better so I could continue reviews, but it’s not. Having to switch manually is breaking my flow, but I guess it’s still better than doing no reviews at all…)
Update: Ah, just saw the GitHub link and that this has already been reported there
3 Likes
This is actually a legacy reason – minimize review penalty was the original behavior. Now we don’t want to change the default on people as that could get confusing ![]()
2 Likes
Just want to say a little (or big) thank you! I’m using Tsurukame almost exclusively and I nearly missed the recent WaniKani update because I almost never use the site for my studies.
I love that all essential user scripts are already in the app and I don’t have to worry about them. I can use the app and study. Without any thinking about scripts and behind the scenes stuff. That’s a big relief and makes my life a lot easier. Really, you are my secret hero.
4 Likes
I wish we had Tsurukame for desktop/Mac OSX! Oh wait - can I install iPhone apps on the Mac OS?
2 Likes