During my lurking, I discovered whisper, which is a speech recognition model that can transcribe audio to text using deep learning stuff. People of course want to learn Japanese from Anime, but that is only really possible with Japanese subtitles, which can be a hit and miss in availablity as the meow website releases don’t provide the Japanese closed captions with the raw video releases. The good thing with Anime is that the voice actresses/actors speak thing clearly, so it can increase the accuracy of the resulting output through AI.
I actually played around with Whisper, but it performs best on Windows. Tried to get it working on a Mac Studio, but it runs slow and the GPU acceleration doesn’t quite work yet. Thankfully, I have a VM with a nVidia Geforce 980 TI pass through. I choose an episode to test this with. I decided to try an episode of Prima Doll, Episode 8. Also, there is a Japanese blog that has most of the dialog for most anime, so I can use that to correct it. I needed mkvextract to get the audio, but once I did that, I’m off to the races.
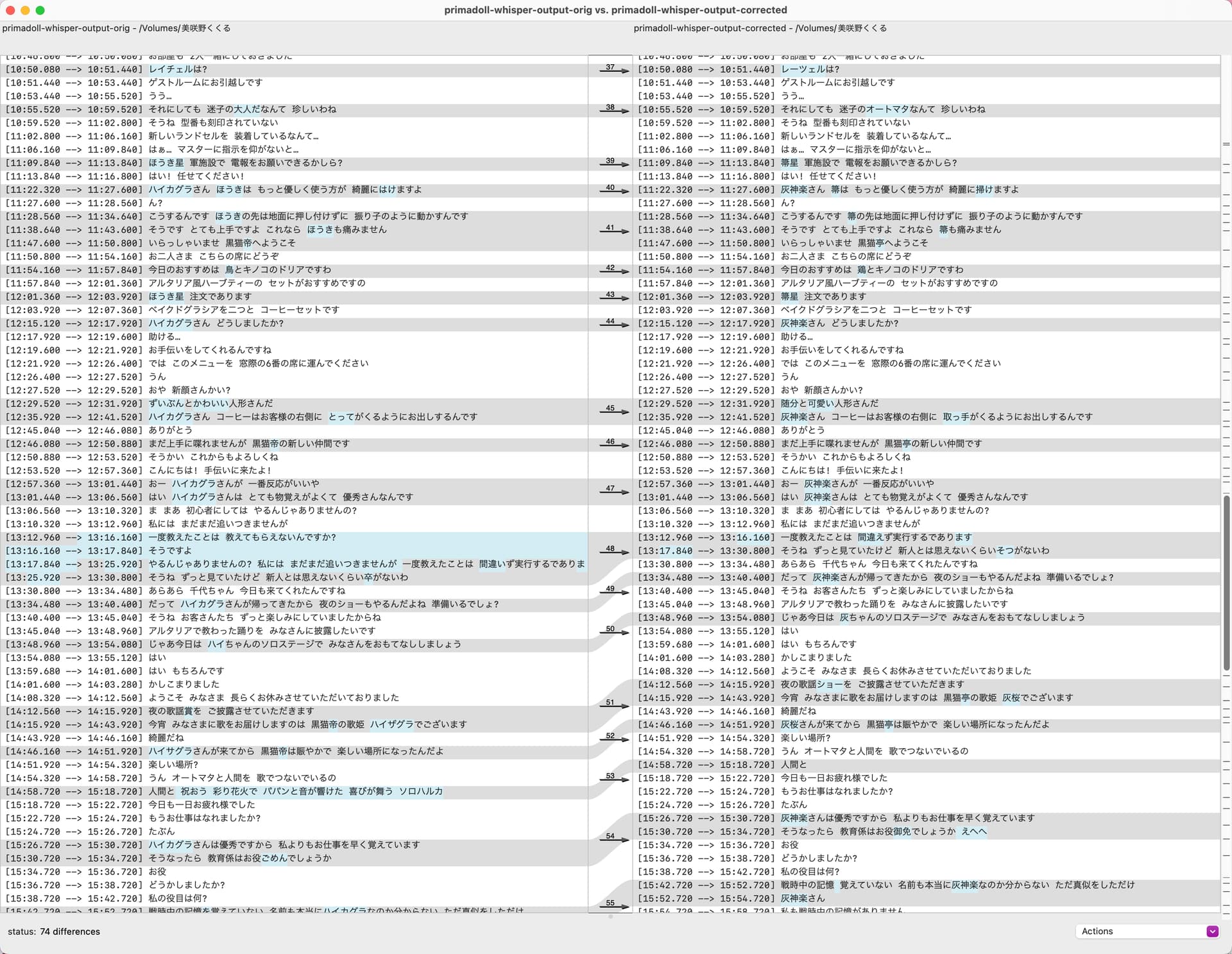
I’m still checking the transcript and haven’t finished it since it’s so late, so the jury is out, but so far, the mistakes are relatively minor, although it messed up a few lines by inserting extranous output. Also, I don’t expect it to handle names of the characters well as it doesn’t know what Kanji to use.

Not looking too bad, except for some corrections, it gets most dialog correct. I think this can be helpful in getting 90% of the way there in creating Japanese subtitles, manual corrections are still needed.
Update I finished the corrections, and the final number of changes are 74. Also, discovered the timings can be a bit off as well and doesn’t handle more than one person talking at the same time.
You can try it for yourself if you have a powerful GPU.
