Looking Back on 2022 and Forward to 2023
SRS
I kind of dropped out of doing SRS. It’s just not a thing for me at the moment.
I figure as soon as Migaku’s new release with their own SRS application (eventually) comes out, I’ll get back to learning new kanji and vocabulary (based on my frequency lists).
Reading
This past year, I wanted to do more intensive reading, which I planned on using 名探偵コナン for. That went well for a little bit until I fell into extensive reading mode…
I think I need to pick something I haven’t read in English for intensive reading. The problem is knowing what to pick. I can easily look up how much known and unknown vocabulary a series has, but I cannot do the same for grammar.
In total, in 2022, I completed 91 manga volumes and one light novel. This total includes both some manga with shorter volumes (140 pages) and some manga with longer volumes (360 pages).
6月のラブレター
Comments
I picked this series based entirely on my knowing most of the vocabulary in it. It’s been a fairly easy read, and I’m enjoying it. The mangaka does a decent job of pacing the reveals, as well as timing them for the end of each volume. I was afraid going into it that the whole “ghost friend” thing might be a bit of a gimmick, so I’m glad to see much of volume two fleshed it out (so to speak).
The only issue I have with the series so far is that male characters have these *super-wide* necks when seen from the side...
2022 feat: Two volumes.
2023 goal: Plan to read the final volume.
ARIA The MASTERPIECE
Comments
Having long ago watched the anime subtitled in English and having read much of the manga in English has definitely impacted my speed on getting through this series in Japanese.
I think another contributing factor is simply reading so many new things that I don’t spend as much time with reading things I’m familiar with (with some exceptions).
2022 feat: One volume (but it’s an omnibus, so it’s kind of like two volumes).
2023 goal: Plan to read two volumes. Actually, that brings me to the end of the series, doesn’t it?
orange
Comments
It’s nice to be reading this one after having it on my “to consider reading” list for a while. I don’t recall where I first heard about it, whether it was a mention on the forums or a recommendation from Kobo.
When it comes to the reading experience, orange is much like アオハライド and 俺物語!! for me in that there are somewhat longer chapters that I tend to read in one go.
I keep going back and forth between “caught up with the book club” and “behind the book club”
2022 feat: Five volumes.
2023 goal: Complete the series, which I’m on track to do with the book club. Two more volumes!
SPY×FAMILY
Comments

I found this one difficult due to the high number of unknown vocabulary words. Even though Mokuro + Migaku makes lookups quick and easy, if I’m looking up too many words then I forget my lookups from the first half of a sentence before I finish lookups in the second half.
I feel like I wouldn’t mind continuing the series eventually, but I think even if I read the kind of manga I like for the next ten years, I still won’t gain the vocabulary needed for this one!
2022 feat: One volume.
SUPERMAN vs飯 スーパーマンのひとり飯
Comments
I’m not into comics about people eating and enjoying food. But the comedic element of a connoisseur cast of Superman made it enjoyable. I don’t plan to continue the series, but it was a fun read.
2022 feat: One volume.
おじさまと猫
Comments
I like the characters and events well enough in this series, but for some reason, I often can’t push myself to read more. I think it’s partly because sometimes I get a bit stuck on remembering who’s who, and distinguishing some of the characters. I have this series on hiatus for now.
2022 feat: Two volumes.
からかい上手の(元)高木さん
Comments

This series is currently my main “something easy to read between reading more difficult things” series as well as my “oops, I didn’t read anything yet today, and I need to get to bed, so let’s get in something real quick” series.
2022 feat: Nine volumes.
2023 goal: Try not to run out of material?
からかい上手の高木さん
Comments

Like its spinoff above, this series is one of my easy reads, only at a weekly pace as I’m reading it alongside the book club.
2022 feat: Six volumes.
2023 goal: Continue reading alongside the book club.
キラキラ100%
Comments

I somewhat enjoy this series, but not enough to feel compelled to keep going, so this one’s on hiatus for now.
2022 feat: Two volumes.
くノ一ツバキの胸の内
Comments

This series does a good job of portraying stories centered around various characters, with artwork that is always lovely to look at, and oh yeah some rather unfortunate outfit designs.
One day, we'll be able to run a whole manga series through AI and have it re-outfit the characters.

(This isn’t quite what she wears in the series.)
2022 feat: Six volumes.
2023 goal: Run out of material and resort to waiting for new volumes. I’m down to one more volume, and I don’t anticipate another coming out until the latter half of the year.
ご注文はうさぎですか? Complete Blend
Comments

This one’s been slow-going as I intensively read the first half at the start of my manga-reading journey back in 2018, and the second half I extensively read over time in 2019 and 2020, on top of having seen the first season of the anime (covers same material) subtitled in English back in 2018.
2022 feat: One volume.
2023 goal: Casually work my way through Complete Blend volume 2. I’d love to make more progress, but I’m reading the higher-resolution Complete Blend releases, so if I go too fast I’ll turn out of material.
シャドーハウス
Comments

If this series had furigana, I probably wouldn’t keep falling behind, as I am enjoying it.
I think the main barrier has been my using Migaku Reader for reading manga, as I can’t do instant vocabulary look-up that way. Anything without furigana, I’ve been reading through Mokuro. Now that Migaku Reader randomly started having issues for me, I’ve switched to using Mokuro for all my manga reading for now. This should allow me to stay caught up. At least, once I catch up again.
2022 feat: Three volumes.
2023 goal: Catch up with the book club and don’t fall behind?
スーパーマリオくん
Comments

I dropped this series after finishing the first volume. I only finished the first volume because I didn’t want to leave a volume unfinished. That’s about all there is for me to say on this one.
2022 feat: One volume.
それでも歩は寄せてくる
Comments

Back when I first started this series (before it was nominated for a book club), I almost read the first volume in a single sitting. At one point, it became a bit of a tradition for me to read each new volume the day it comes out. I’m looking forward to the next volume’s release while enjoying slowly revisiting the material in the offshoot book club.
2022 feat: Five volumes.
2023 goal: Maintain status quo.
ちいさな森のオオカミちゃん
Comments
This made for a nice easy read, but I do admit it didn’t hold my interest very well. I expect I would have enjoyed it more if it was one of my first manga read in Japanese, and as such I’m interested to see if it gets picked and enjoyed by new readers in the ABBC sometime.
2022 feat: Two volumes.
ないしょのプリンセス
Comments

This is from the same mangaka as キラキラ100%, but so far I’m enjoying this one more. Things took an interesting turn right at the last page of the first volume, and if I wasn’t focused on finishing up every volume I’m in the middle of for year-end I would have started volume two already.
2022 feat: One volume.
2023 goal: Read the last three volumes.
ななか 6⁄17
Comments
The male lead character in this series is a bit difficult to understand with his “tough guy” way of talking, but I’m toughing it out. Still, that’s making me less likely to read it. I enjoyed the anime long ago, so hopefully I’ll start to really get into reading the manga over the next volume or two.
2022 feat: One volume.
2023 goal: I don’t have any specific goals in mind for this series, so perhaps just keep going forward reading it?
にじいろフォトグラフ
Comments
This one I managed to spread out over a long time, as it didn’t capture my interest much. I’m undecided about whether to give the second volume a try. If the first volume ever gets picked for the BBC and gets an offshoot club, I’d read along.
2022 feat: One volume.
ハナヤマタ
Comments
I enjoyed the anime for this series enough back when I saw it that I decided to make reading the manga (which lacks furigana) a goal of mine. I think maybe it was intended at the end of 2019 to be a 2022 goal, as I didn’t consider how difficult it would be for me to learn certain kanji, and thus hit a lack of progress in WaniKani. That said, one volume in, and it’s going better than I expected!
2022 feat: One volumes.
2023 goal: I don’t have any specific goals, aside from continued reading.
ひとりぼっちの○○生活
Comments

I like that this series is a fairly easy read, but the lack of furigana gets in the way when I happen upon an unknown kanji. Now that I’m using Mokuro more, I expect to make good progress in reading this series going forward.
2022 feat: One volume.
2023 goal: Perhaps complete two volumes?
ヒビキのマホウ
Comments
This series fits squarely into “I wanted to like it going in, but it just isn’t catching my attention.” I’m undecided whether I’ll continue reading it.
2022 feat: One volume.
ふだつきのキョーコちゃん
Comments

This series went by so fast… I feel like I can see myself reading it again in a few years, but if I have other things I’m focused on reading then maybe not?
2022 feat: Seven volumes.
ふらいんぐうぃっち
Comments
One volume per year. I’m looking forward to reading more in a few months.
2022 feat: One volume.
2023 goal: Learn the magic spell that allows mangaka to increase their productivity.
ポケットモンスタースペシャル
Comments

Waaaay below my planned reading for this series. This volume had too many characters speaking with a dialect, role language, etc. for me to feel up to reading it each day or week. There’s just one more volume in the series with the current cast, then hopefully the next cast will be a little easier for me to follow.
2022 feat: One volume.
2023 goal: Finish up the Kanto series (one more volume) and start the Johto series. No specific volume count goals at this time, but I hope to at least reach the volumes with legible text!
まじっく快斗
Comments

I started reading this one because I figured the difficulty would be similar to 名探偵コナン, but where I’ve read half of that series in English, this one I haven’t.
The difficulty has been higher, but that’s partly due to the overly casual way some characters speak.
Storywise, まじっく快斗 feels like fantasy and science fiction compared to 名探偵コナン feeling “real-world” (aside from the whole poison-turns-teenager-into-child thing). It’s a bit jarring considering the two series co-exist with Kaito Kid crossing over into Conan’s stories from time to time.
2022 feat: One volume.
2023 goal: Aim to finish the series, which is four more volumes.
俺物語!!
Comments

I enjoyed the series, even if some chapters were a bit slow.
The final story arc felt a bit rushed/sloppy to me, but it wasn’t bad, and it led up to a nice finish.
2022 feat: Two volumes.
名探偵コナン
Comments

I feel like I should have gotten in just one more volume to average one per month.
The number would have been even higher except I took a few breaks from Conan to avoid it overtaking all my reading time. I look forward to running out of material to read in about a decade.
2022 feat: 11 volumes.
2023 goal: Perhaps aim for an average of one volume per month.
夜カフェ
Comments
I’m glad I stuck it out until the end of the book, but for now, it looks like I’m focusing on manga.
2022 feat: One volume.
好きな子がめがねを忘れた
Comments
A new volume is out in January!
I really enjoy this series, but considering it doesn’t start to really get good until maybe volume 3 or 4, and at its best it’s still only average, it’s hard to recommend it.
2022 feat: Six volumes.
2023 goal: Don’t read more than one chapter in one sitting.
幸色のワンルーム
Comments
The characters and story haven’t compelled me to continue, so this one’s on hiatus.
2022 feat: Two volumes.
怪獣のトカゲ
Comments
I forced myself to complete a whole volume, but I’m not interested in continuing the series.
2022 feat: One volume.
恋に恋するユカリちゃん
Comments
I was surprised to find the series ended after only five volumes.
Although they move to different story beats, anyone who likes からかい上手の高木さん would probably enjoy this series.
2022 feat: Two volumes.
現代魔女の就職事情
Comments
After forcing myself to push through to the end, this series qualifies as “I wanted to like it more than I did”. The artist did a good job with it.
2022 feat: Two volumes.
藤代さん系。
Comments

After taking a long time to get through volume one, I figured my improved reading ability would make volume two more enjoyable. And yet I slowly worked my way through it over much of the year. I’ve put this series on hiatus as well, as I just didn’t feel compelled to continue.
2022 feat: One volume.
New Series for 2023
For 2023, I’m adding to my reading list:
Colori Colore Creare: Picked at random. It’s from the mangaka of ARIA. I don’t know if it’s a one-shot volume, or if it’s still ongoing.
ストロボ・エッジ: From the mangaka of アオハル. I’ve been meaning to read more of their work. This series came out before アオハル, which I figure is the better side to start on in case the latter works are much better than the earlier works. If I like the series, will I read through all 10 volumes in one year?
古見さんは、コミュ症です。: I figured I’d read this one regardless of the Beginner Book Club poll results. Since it won, it looks like I’ll be reading it with the club at club pace. This is a fairly long-running series, so we’ll be reading it for years to come!
夢みる太陽: Random pick from orange’s mangaka. I may start this while we’re on break between orange volumes, as there seems to be a crossover story with this one around the end of orange. This series is completed with 10 volumes, so if I like it maybe I can finish it within a year.
春色アストロノート: This one comes included with orange, so I’ll likely read it after finishing orange.
日々蝶々: I have no idea what to expect from this one. After I finish up 6月のラブレター, this is next on my list of “I know most of the words and kanji, so it should be an easy read” manga.
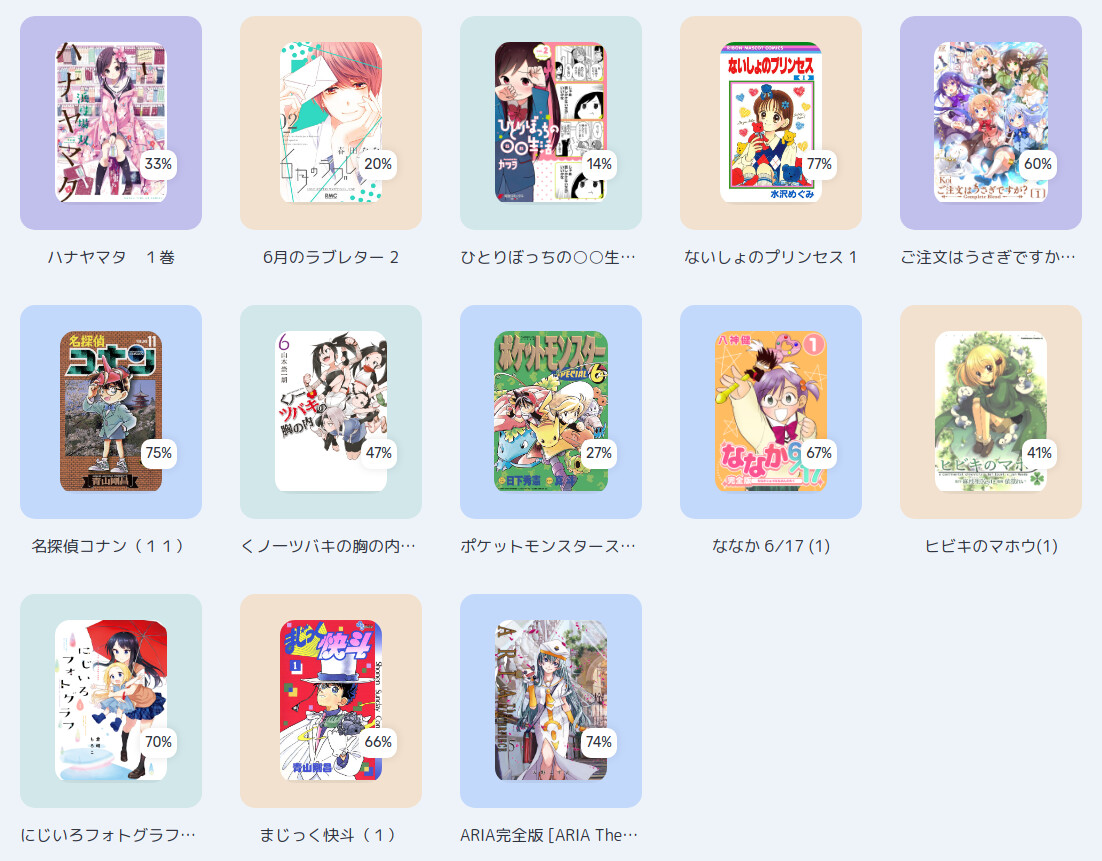
2023 Book Covers
Here’s everything I’m looking to read going into 2023:
Listening
I decided on a spur-of-the-moment whim to start listening practice.
Some time back, I was watching some anime for practice, but that was mostly reading along with the subtitles.
The plan for this time is to watch with scripts for the following:
- Pause at the end of each line of dialogue.
- Press key to re-play line of dialogue.
- Press key to show subtitle and re-play line of dialogue.
I wonder if I can get this to tie in with Migaku somehow so it skips over dialogue with words I don’t know, so I can focus on lines where I know all the words.
Programming
I’ve started two small projects this year, both recent.
As I work on these projects, I often find that learning how to implement something on one leads to improvements on the other.
Wanikani Book Club Manager
This recent project is a tool for managing book clubs, including reducing posting each week to a few clicks.
Comments
Whenever I think I’m getting close to being able to bump the version number up to 1.0, I notice more things that absolutely need to be implemented before I could expect anyone else to consider using this. Not to mention to make it easier for me to use with future book clubs, as my current templates include some series-specific data in them.
Mokuro Bookshelf
This recent project is a single-page document that auto-tracks my reading process when using Mokuro.
Comments
This replaces Migakur Reader for me for reading manga, so I’m looking forward to seeing how I improve it (slowly) over time.
Website Post Builder
This one’s specific to my Japanese-learning website.
Comments
Since upgrading my site to use templates, and having improved my post builder tool further, posting content to my site’s become a lot easier. I don’t know how much I’ll post on it in 2023, but between this and some other tools I’ve written to streamline the process, all friction has been removed from the process. Now it’s just a matter of laziness on my part.