Newly-added setting:
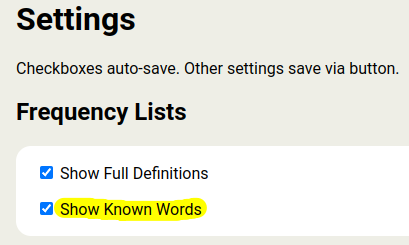
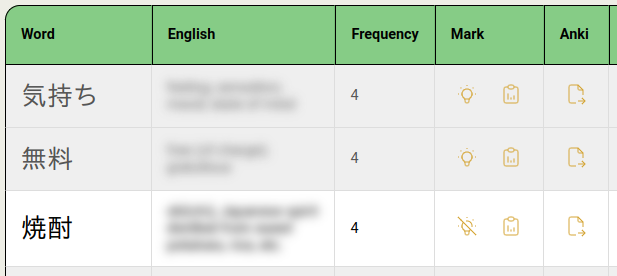
This currently only applies to word lists.
The kanji lists need a lot of clean-up before I can properly add support for showing known items there.
Newly-added setting:
This currently only applies to word lists.
The kanji lists need a lot of clean-up before I can properly add support for showing known items there.
Ummm… so what I said was
But you’ll notice I didn’t say the reviews worked… because I had done them for the day and didn’t think about that part.
Here’s how the review looks.
I was trying to play with the note template yesterday to fix it, but discovered the previews come up fine on my pc, but they are aren’t on mobile. So I’ll play around a bit more and if I can figure it out I’ll let you know
Haha, me too, I’ve decided not to mark words as known until I’ve definitely recognised them outside of manga kotoba
That’s a good question… I guess since known words are already removed, I wonder if one per page is good, as there could be a lot of unknown 2 occurrence words that appear in different chapters.
That’s totally fair, and I can imagine if there was a way to make a mini campaign now and then, ie, for a new offshoot bookclub, people would consider contributing as a group. Not as much hassle as a kickstarter. Maybe a patreon with a good enough description, ie, someone could organise a vote on wk to figure out if there’s enough interest, and cost per person, and then once they’ve sorted themselves out and it’s just a formality of a payment, there could be some way for people to pay in.
That’s really generous!
Hmmm I was thinking of pages at the time, but actually, as above, if there’s an option to show words in order of appearance and they are list on each new page they appear, then it will be easy enough to figure out where you are in the list (dare I ask for a bookmark feature) so this is actually already covered.
Let’s say I’m on the page for volume 1 of Frieren but inow want to go to Tongari 1. I have to click Dashboard, then Tongari, then Volume 1. It doesn’t sound like a big deal and it’s not really, but I feel like the most friction in clicks is going between volumes. An easily accessible shortlist menu would be really cool. Although maybe that’s just me. If someone is more interested in the series level data then it’s already fine.
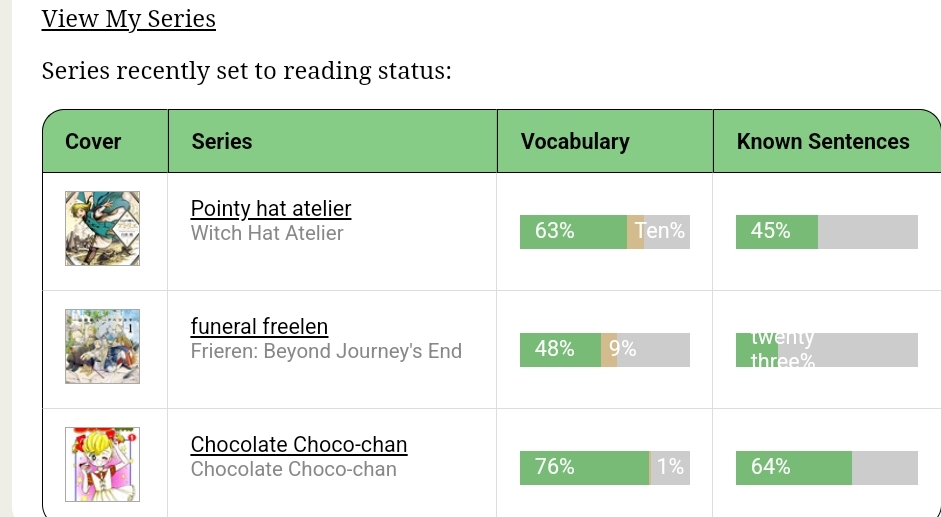
Ooh that will be fun! I don’t know if it’s related but recently some percentages show up with text numbers
Looks fine on my end now!
OK glad to hear!
Wowzers! I’ll do some browsing…
That is fun to turn on for confidence building ![]()
Edit:
I’ve played around a bit more, and I think this feature is really useful! It’s possible a bunch of words are marked as known at one point in time, but then later after reading other stuff, they might have been forgotten.
I found a bug in the visuals.
When this feature is on, then if you click on the light bulb to know or not know a word, it does correctly change it’s status, but it doesn’t visually toggle it.
So let’s say 猫 shows up as known. I hit the light bulb to toggle it to unknown. It still shows up as grey / known. But if I leave the page and turn off the feature and come back (um… or just refresh it), it now shows up as white / unknown as it should. Likewise with an unknown word. If I click it, it doesn’t switch visually to a grey known word, but it will if I refresh the page, and it correctly appears on my known words list.
I’ll have to look into this and see if I can reproduce it.
By the way, I actually do have in mind having a way to view words by page. For me, this would be useful to recognize certain types of pages, such as the copyright page, to mark as excluded (once I implement excluding pages).
And once I implement that (whenever that may be), having an option to view words in order of appearance, split per page, becomes easier.
Then the question becomes, do I have an option to switch between the two, or do I have links to two separate pages, one a volume frequency list, and the other an in-appearance-order pages vocabulary list?
The only downside is the pages wouldn’t be numbered, because that would require mapping the numbering of the file names of the pages from the EPUB file to the page numbers on the images, and some manga don’t even put page numbers on the pages (especially for digital releases).
Although it’s not something I foresee implementing, it wouldn’t be difficult to at least mark the page someone’s on in reading if they are able identify it, with the ability to typing in a few words from the manga page to locate the matching page on the site.
While I don’t plan to implement this at this time, I can see the end result working similar to a static book club vocabulary list. Not a replacement, as the Google Sheets vocabulary lists allow adding words that OCR/Ichiran miss, and correcting mistakes, but for someone reading a manga without a book club, it would result in a tangentially similar experience to a book club vocabulary list.
My current planned solution for this is:
I just need to actually implement the volume-level status and how it interacts with the series-level status.
Offhand, it may sound simple enough. You’d only ever be reading one volume at a time from a series, so there can be an option at the user/series level (in the database) that tells which volume is currently being read, right?
By the way, I’m reading both of these volumes at the same time:
Well, technically I finished volume 7 and now I need to buy volume 8 to continue.
The volume between 6 and 7 is sort of a single-volume spin-off that was released between the two, and involves side characters, and starts out before the events of volume 1 with some time-skips along the way, without overlapping events from the main series. So, it can easily be read concurrently with the main series.
Suddenly, allowing only one volume of a series to be marked as “reading” doesn’t quite work!
I could still have it so if a numbered volume is “reading”, then the user marks the next numbered volume as “reading” that the prior one marks as “complete”, which hopefully would work out.
I’m always looking for ways to get around and to where I want to be in few clicks. (This is why the old site has the option for tracking specific volumes.) At least this one I can say, a way to quickly access all the volumes you are reading is planned.
Is Google Translate running on the page? I ask because the Japanese titles are translated. It’s likely that Google Translate is helpfully(?) converting the numbers to text (because…it’s helpful?)
When you reach the point where page 1 of words are 100% known, you get the sense of “wow, I know a lot of words” followed by “now I have to do extra clicks to find the words I don’t know…”
From the admin side, too.
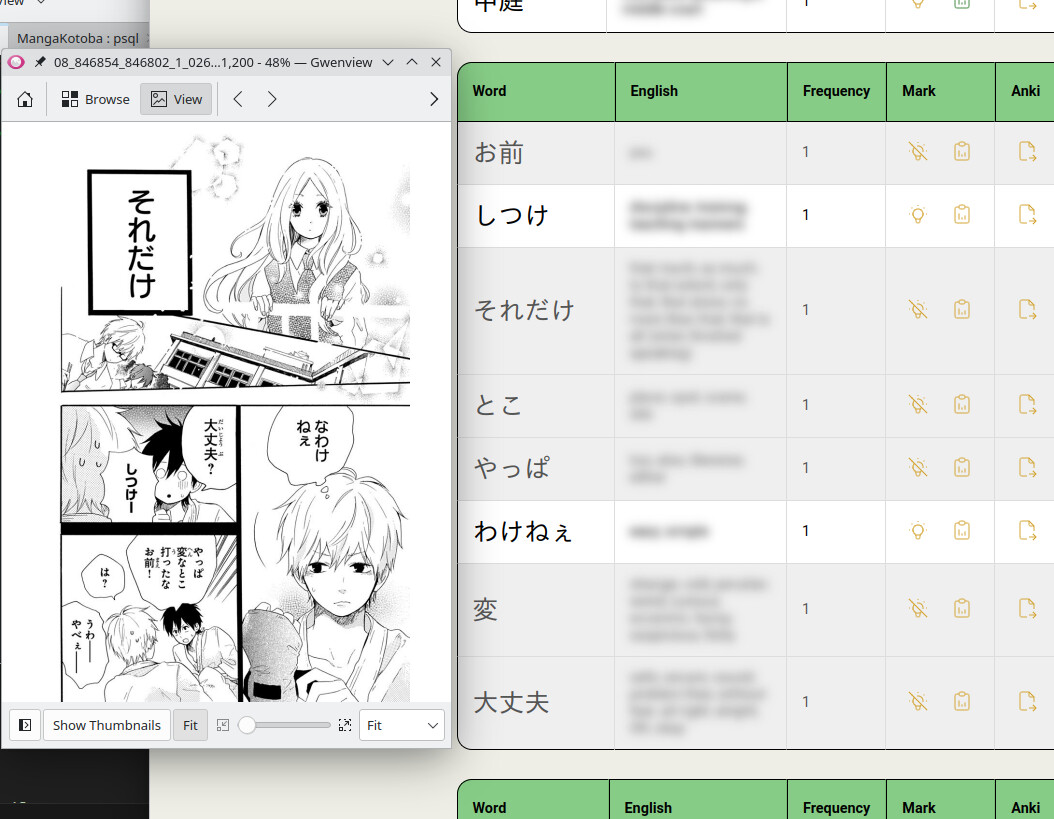
One series I added, a character’s name has two kanji. I found the latter kanji at the top of the frequency list showing me it was misparsed. But the other kanji in her name was 花, which I know I already have marked as known. (I do have a separate admin account where I don’t mark any words as known for exactly this purpose, but I never switch between accounts…)
Enabling showing known words let me see 花 did have a very high frequency due to being part of a name, so I was able to block it for that series.
I know how this can be…
Currently, the image (is supposed to) change after the database updates the entry, but I think it may be better to have the image change upon click and before the entry updates. It’s something I’d considered, but I haven’t had enough time to see if the current implementation was going to be an issue. I didn’t come up in my minimal testing on the site, but I’ll keep this in mind to adjust.
Also, some new settings I’m testing so I don’t keep seeing series I’ve already finished on the main browse page:
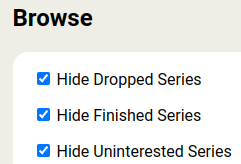
From the user perspective, these options are about the same, but the toggle may be quicker to access
That’s OK, although the bookmark would make that easier
That’s what made me think of it, too! The club sheets you make are so useful, and manga kotoba can get most of the way there plus is more personalised…
There must be so many things like this! Actually marking “reading” multiple volumes of the same series at the same time could also be good when you’re finishing one but already learning the vocab for the next. Or sometimes I reread previous work.
Doh, good catch. for some reason it started autotranslating whereas before I had to request it and its breaking everything. I need to get that turned off globally
That is fun! Almost there but not quite!
Haha I saw that! It’s always fun to discover new features! You’ve made a ton of updates
It seems to me that I’ve read the suggestion somewhere, but is there a way to undo a “known” mark on a work ? It’s easy to click acccidentally on a word and to send it into the known list (is there a way to have access to this list, by the way ? EDIT : I found a way to acess you whole list of known words on the home page ^^)
Otherwise, this is a great data base ![]() I’m just beginning to explore it.
I’m just beginning to explore it.
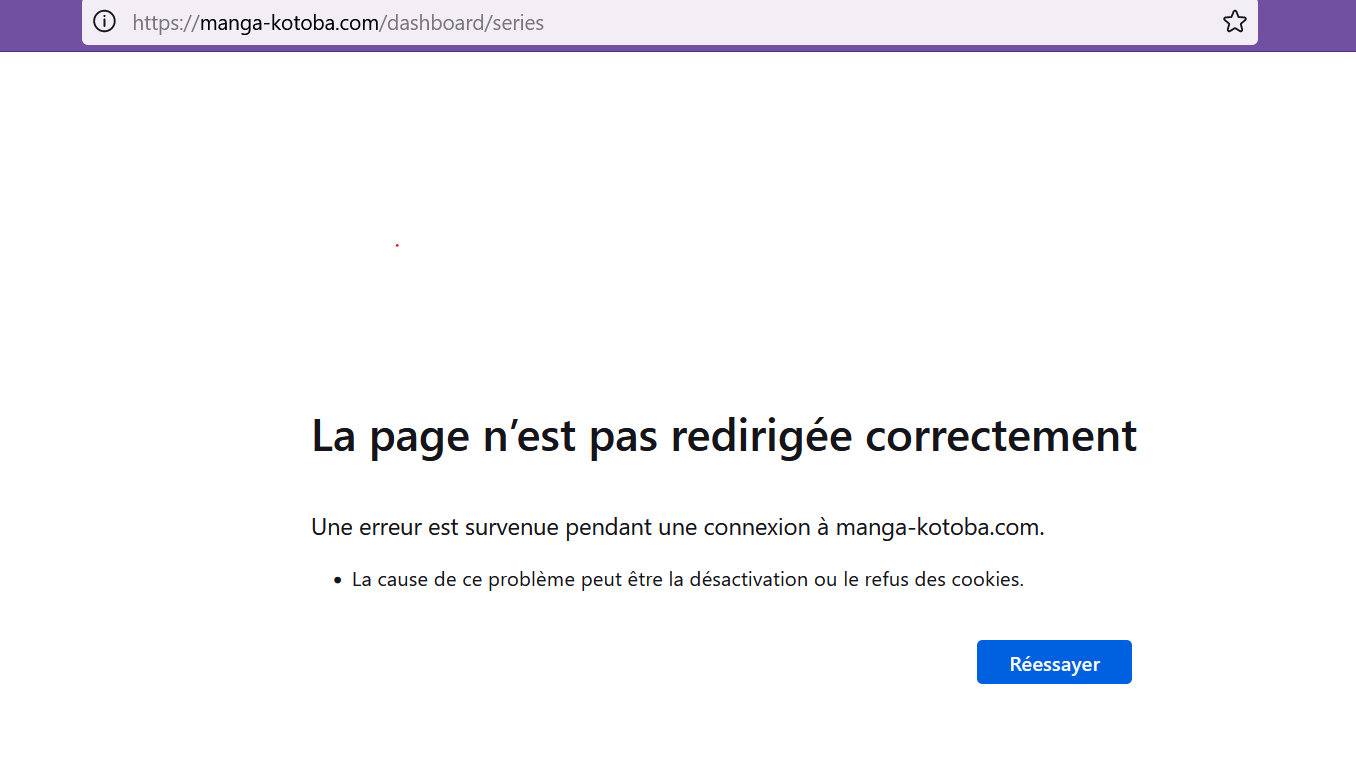
Also, when I click on “view my series” on homepage, I get this message :
(I didn’t refuse any cookie, and I checked it to be sure)
I’ll see if I can reproduce this. It’s probably due to a new value I added to the database tables that I need to update some code for.
Current work (not yet live):
I’m not quite sold on it as something to keep, due to a few reasons:
Lack of page numbers. Adding a number to each table of words is quick and easy. Matching it to page numbers in every manga series and volume is not so quick, and including for manga that don’t use page numbers is not so easy.
Words being in a different order than one the page is a bit disorienting. I can sort them by word, but I don’t yet have a good way to sort them by reading (regardless of kanji usage).
This expose some cracks: some words are missed by Mokuro or are misparsed, and some words get excluded from the site for various reasons, and this tends to be hidden when looking only at the higher-frequency words.
Adding a condition to my current database query to group words by page. But that loses the per-volume frequency numbers, so I might need to write a separate query just for this functionality.
I’ll update the note style on the site in the next move to live, but for now you can manually update the note style:
Front template:
<main>
<div id="header">
<div id="type">Vocabulary</div>
</div>
<div id="card">
<div id="target">{{editable:Target Word}}</div>
</div>
</main>
Back template:
<main>
<div id="header">
<div id="title">Vocabulary</div>
</div>
<div id="card">
<div id="target">{{editable:Target Word}}</div>
{{#Reading}}
<div id="reading">【{{editable:Reading}}】</div>
{{/Reading}}
<div id="definitions">{{editable:Definitions}}</div>
{{#Example Sentences}}
<div id="sentences">{{editable:Example Sentences}}</div>
{{/Example Sentences}}
{{#Images}}
<div id="images">{{editable:Images}}</div>
{{/Images}}
</div>
</main>
Styling:
* {
background-color: #eaeae2;
}
html, body {
overflow: hidden;
}
main {
min-height: 100vh;
min-width: 100vw;
}
.card {
font-family: arial;
font-size: 20px;
text-align: center;
margin: 0;
}
.nightMode * {
background-color: #000;
}
#header {
font-size: 0.75em;
text-transform: uppercase;
font-weight: bold;
text-align: left;
color: #fff;
background-color: #d4a637;
margin: 0 0 10px 0;
padding: 0.5em;
border-bottom: solid thin black;
}
#header * {
background-color: inherit;
}
#card {
color: black;
background: white;
margin: 0 1em;
padding: 1em;
border-radius: 25px;
}
#card * {
background-color: inherit;
}
.nightMode #card {
color: #bfbfbf;
background-color: #1e1e1e;
}
#target {
font-weight: bold;
font-size: 2em;
margin-bottom: 0.25em;
}
#reading {
margin-bottom: 0.5em;
}
#definitions {
margin: 1em 0;
}
#sentences {
font-size: 1.25em;
margin-bottom: 0.75em;
}
#images {
}
I haven’t been able to come up with anything that might cause this.
Do you still get this error? Does it appear in a different browser, or on a different device?
I’ve just tried, and now it works. But I had this error for several days in a row (on my laptop on firefox). But everything seem fine now ^^
It’s not a must have, but I’d still put in a strong vote for it. I’ve started using this feature on jpdb and it’s useful if the words are easy enough to find and have global frequency info. Then instead of pre-learning everything, there are some words I wait to see in context because I’m just not super convinced until I see them in context how useful they are. In context, often it turns out all 5 occurances are within 2-3 pages and it’s hyperspecific to a certain event. That’s a lot different than if it looks like something that will come up once every chapter.
This doesn’t currently bother me on jpdb, I just leave one version of the site open to where I left off, so it really doesn’t matter. I guess the problem is if I ever lose my place… but I just make a note on my reading page which jpbd page it corresponds to and so far that isn’t a problem.
That’s a tough one. Hopefully the number of unknown words per page is pretty small, though. For a new reader, maybe up to 10 if they are reading something easy enough, and later it goes down a lot. If it’s just 4 words the order doesn’t matter much. getting much more than 10 it probably starts to fill more than one screen and get annoying.
I can see how from the development side that’s annoying. From the user side, I feel like, well, of course there are misparsings, and I want to know that before I bother learning them. Seeing them in context helps to know what can be safely ignored. It might mean that you need a button to ignore or correct an entry, though.
So that and the additional script you need for the global frequency query maybe it’s not worth it… It could be something to ask in the middle or at the end of a book club. How many people used the book club spreadsheet and felt they benefited from the ordering of the words as they read? Not sure how else to get more feedback on that one before you put in even more programming effort.
I’ll have to try that again, thanks for the fix! The error itself was showing up during my reviews, not in the browser, but I was creating the cards from Chrome. I’ll have a look.
The (current) Anki cards appear correctly on desktop Anki, so the blank card error is on the mobile version only.
The template and styling fix you sent wouldn’t save (doing that from desktop). It said there was some field error. I’ve only ever done minor adjustments based on other people’s templates, so I have no idea how to debug that!
Oops, the forum furigana userscript broke the HTML. I’ve fixed it in my prior post!
Just tried this tool and it’s great! I love being able to track my known words between a variety of media in JPDB but always felt like it lacking manga was a huge thing it was missing, so this tool is perfect for looking up high frequency words of something I’m interested in. (It will take me a while to mark all I know as known but I will prioritize series I’m actively reading)
I’ve noticed an error, not sure if it’s been brought up in the thread: clicking on Browse breaks the page completely.
I will surely be using this, separating the words by manga volume works great!
I’ll have s look thanks!
Maybe write in which browser you’re using? I haven’t had this problem (chrome, Firefox or Samsung)
It was on Chrome, but it appears to work fine now. Some series appear at 0% vocabulary until you click on them though
I’m just another user - for me all the series showed zero until I click on them. Then they show up at the end of the list in % order. So if I open one, I make sure to mark it if I’m interested as otherwise it’s hard to find again
I’ll have to play around with this and see if I can reproduce it. Sometimes issues occur if a user’s stats haven’t been calculated yet, and it’s difficult for me to catch these without wiping out all my stats and seeing how things go.
In some cases, the site is serving you a page first, then calculating the stats second. I haven’t yet figured out how to properly implement updating the stats via Javascript once the calculation finishes, but subsequent page views get the updated stats. This is an area I want to improve over time as I learn more about utilizing various technologies.
This is another issue I’m hoping to resolve. I haven’t yet narrowed down the cause, but it’s likely the user’s percentage value for each series isn’t being stored in the database until a word from the series is marked as known. It’s on the long to-do list!
Yes, I had just created my account and the error mentioned something about “hide something” not being defined, so it was probably looking for something that hadn’t been calculated yet.
This is now resolved. Thanks for letting me know about it!
It was related to dark mode, so hopefully the fix works. I tested it in my smartphone with dark mode enabled and it’s looking good there.
The setting to view words per-page is now live. It’s still lacking the volume-level frequency information, but you can try it out and if there are any suggests/recommendations, feel free to let me know!
I do consider this to be a huge limitation of a volume-wide frequency list. There’s nothing telling you how grouped-together or spread out the occurrences of the word are.
Although I don’t plan to implement anything to address this, it’s an interesting problem to think about.
For example, if I calculated the mean (average) page number for a word, then calculate the standard deviation, I could tell if a word in a volume is localized to one chapter versus spread throughout the volume.
The question becomes, can I do all this via a SQL query that stores the results? Or should I do this in Python when I extract the data (volume level only, not series level) and store that data in the database?
This is where having a “bookmark” option and a UI to go to the bookmark would help. It’d be an option that allows setting one bookmark, and then setting a new bookmark replaces the old one.
I don’t have any plans yet to implement this, but if it looks like this “show words in order of page of appearance” is viable, it will be open to improvements.
Another consideration: When known words as hidden, marking a word as known hides that word’s row. When viewing per-page, a word can be shown on multiple pages, but only one instance becomes hidden when marking a word as known. I’ll need to updating the Javascript code so it locates and hides all instances of the word on the page. Easy enough to do; I just need to make the time for it sometime.
This is my hope as well.
When someone first starts out, there are going to be many pages per page, but the volumes goes down surprisingly fast when learning the most common words.