@jhol613 Thank you too, same, glad to hear! I also use this mainly for games, haha. Maybe physical books soon.
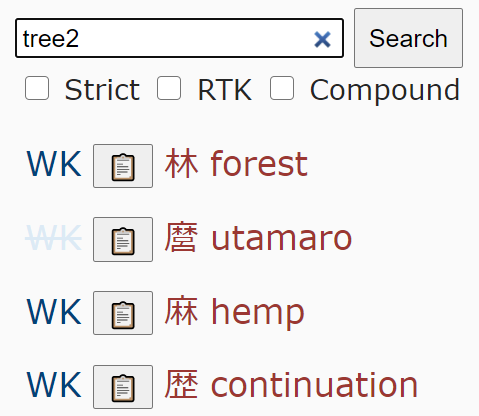
Oh and a pro tip: if the radical occurs multiple times, add the number to its name.
e.g. tree2:
or mouth3, mouth4, sun2, sun3, etc.
(i also made it so you can type 2tree etc., but that way you won’t get results until you type the complete radical name)
Tell me if there’s a kanji you can’t find this way!
Tab (and Shift+Tab) now switches from Search bar to Compound bar first, then delete & options. Up and Down Arrows select/copy result, Enter copies first result. In compound mode, selection is only copied by Enter.
(gifs created with ShareX. ~169/50KB)
All WK kanji are now actually findable by name some with partial radical name hits like “long time” or no (否) weren’t found until now. Also, RTK and Jisho don’t consider the repeater 々 a kanji. (That may be correct, but it’s listed as a kanji on WK, so i added it)
Results show keyword matches and more common variants first.
Kanji count: 3052!
(hopefully more kanji added more quickly soon, looking at the Aozora most common 2000-3000)
Fun fact: Both Xenoblade (Chronicles) and Xenoblade X (Nintendo games) casually show 蹂躙 in the intro. Neither kanji is in the RTK 3000. Added as 3049 and 3050.
(Well, it’s spoken out loud and only appears in the subtitles, so if you’re a Japanese kid, probably no problem )
I haven’t given an update in a while, but don’t worry, i’m still working on this.
We’re now at 3069 Kanji, number 3068 and 3069 fittingly being 揶 tease and 揄 tease, which gives 揶揄 banter/teasing, and more commonly 揶揄う to tease, to make fun of, etc.
Currently working on a feature to show you the radicals for each kanji. Something like this:
It will display the biggest units, e.g. for 院 it’ll give ‘building perfect’, while you can click on ‘perfect’ and it will show the further breakdown into ‘roof origin’.
I hope it will be useful, especially when you forgot a radical.
After that i’ll probably first focus on getting a lot more kanji in, like the Aozora top 2000 (63 missing), and perhaps another frequency source like News/Twitter/Wikipedia from here.
I’m a bit worried that this project will be made obsolete by optical character recognition. But as i wrote in my initial post, OCR can still be inaccurate and tiresome, and even with perfect OCR, this would still have applications (e.g. ‘show me all kanji using the radicals xy’).
edit: the search did just show me very quickly why i was confused about 部 being part, not accompany
Now at 3083 kanji searchable!
And hopefully the pace of kanji adding will pick up now as well, because I implemented some systems that make it easier and more meaningful.
A kanji’s radicals are written down as pure versions only: For 易, instead of writing *easy, sun, wings", I can just write “easy”, and sun and wings also work for search, because they are filled in when using “easy” (e.g. for 湯).
This has even more usefulness for RTK radicals/elements, which I’m using instead of WK radicals to catalogue the kanji. They have a lot of synonyms.
I also catalogue a kanji’s structure now. For example, 易 (easy) is top-down(sun, wings).
関 is outside-inside(gates, top-down(horns, heaven)).
This is not immediately the most useful, but if I’m cataloguing kanji’s radicals by hand, I may as well include the structure. Potential applications are differentiating 陪 and 部, or showing the user the structure of the kanji, so that they can see which radical in which position has which name. Maybe you’ll be able to search by the structure as well.
Eventually I plan to add this information to kanji 1-3078, which were written without this and mostly without the “pure” notation in the above bullet point, though at least for the structure I may wait until it becomes useful.
I had a feeling that the way I catalogue kanji would change, which made me slow down the pace, but now that I feel good about it, I hope I’ll add a lot more kanji a lot faster soon!
Also, happy new year!
Update 1.5: A wild radical appears - or why Switzerland is bad/evil (just kidding!)
We are at 3100 kanji now!
And I stumbled on an interesting kanji: 惡
This one has a new radical that’s hard to represent with existing WK/RTK radicals,
so I decided to give it a new name: Swiss. You know that country, Switzerland? It prominently has this shape in its flag.
I also gave it alternate names that are automatically added: switzerland, red cross, plus, and d-pad (gamers represent!). It’s also found by convex2, cage4 or simply cage. Boy, that’s a lot of synonyms!
I think I’ve seen this radical before in other kanji, isn’t there one that is purely this (swiss) cross?
Other than that the changes were mainly in the backend, nothing too exciting for the users, but it’s making it even faster for me to enter new kanji.
I created a script that automatically generates a new kanji entry with all the obvious data filled out:
(If you’re wondering about this structure, it’s inherited from the old codebase, and it’s using Jekyl/Liquid)
After this I only need to add the elements info and check for variants/alternate.
these are RTK elements, read: top-down(ground, swiss, ground, heart)
I really should have written this script a long time ago. But unfortunately, me not so smart! ^^
The kanji info is downloaded via JSON using https://kanjiapi.dev/ - awesome tool for developers!
(the API is not used on the website, only once by myself when I add the kanji)
And now that we improved the kanji data entry process again, we should be able to increase the speed
of adding new kanji once more!
This is amazing! I had this idea the other day when struggling to find radicals on Jisho’s search by radical. This is so much more convenient and faster for those of us who have already memorized the Wanikani radical names.
Thanks, that’s great to hear! I’m happy this is useful for some people. Hopefully there will also be a lot more kanji added soon though it’s starting to get extremely rare that I find a kanji in any media that isn’t in the search yet!
It’s great how comprehensive it is although more kanji is always great too! One feature request: sometimes the kanji in the source material come with furigana and it’d be nice to be able to filter by the pronunciation (in hiragana/katakana/romaji) to identify the correct one quickly (I realize I can just search Jisho by pronunciation, but sometimes there are just a lot of options to go through, or the furigana are tiny and a little hard to read completely). This would also useful in cases where I am writing and I remember at least one radical and also the pronunciation but not the entire kanji.
Ah, I see, filtering by reading/furigana does sound useful in some cases. Will see if I can add it
And thanks for posting to this reddit! I had always thought about doing that at some point, but never got to it, and always wanted to add some more improvements before doing so, haha. But I don’t mind at all. Curious what reaction it’ll get.
One more suggestion for something I just noticed: certain radicals are composed of other radicals. For example, dance is made up of cow and evening. Me not yet being level 36, I hadn’t learned that radical yet, but I recognized the cow and evening radicals. It’d be nice to be able to search by these “constituent radicals” as well as by the combined one.
Finally, this suggestion is more complex since the data would have to be generated by hand, but it’d be really nice if for each radical you could specify its position in the kanji to narrow things down faster (e.g. top, bottom, left, right, vertical center, horizontal center, lower-left, lower-right, upper-left, upper-right).
For example, imagine you type rain wolverine, and it then lists the two radicals with a series of boxes next to each one with various different kanji layouts. One of the layout boxes is a 1x2 layout, and you simply click on the top part for rain and the bottom part for wolverine. This is particularly useful when you only recognize one radical and not the others since one radical + position can narrow down a lot.
Hey, you should already have been able to use the subelements of radicals, like “evening cow” instead of “dance”. There was just some data missing for “cow”, it works now:
Make sure to refresh the page, and that it shows v1.5.3.1 (or greater) in the footer.
And please continue telling me when things don’t work as expected!
Cow was not in the data for these kanji because RTK is much more strict with the exact shape of elements/radicals. You’ll notice that the original shape of 牛 cow is slightly different in 傑 greatness. WK says it’s similar enough to still be “cow”. And I like this leniency, which also makes it easier for searching. In RTK it’s easy to search for the wrong variant if you’re for a moment not aware of the differences, e.g. 衤in RTK is cloak and ネ (or 礼 left part) is altar (missing the tiny stroke in the middle), but in WK it’s both spirit.
As for searching by position of the radicals: I’ve been planning exactly that! But you’re right, the data for that has to be added by hand, and I only started recording this positioning data from about kanji ~3070, so I still need to add this data manually for all the other kanji. But it’s definitely planned and can be very useful in future.
Aha I see now was just a missing data issue If you need any help with data labelling for positioning data I can definitely help with that, just let me know the kanji set and what format you want the data in.
Thanks for the offer! The dataset uses RTK radical (element) names though, so this might be too much of a hassle for WK users to ask for, haha.
I extracted the data into a google spreadsheet anyways:
The ElementsTree column should contain the positioning/element data. If not present, Elements is used. (just the elements without positioning data)
The structure is like this: l(person, two) means left to right: person, two → 仁
l(person, t(horns, dry)) means left to right: person, top to bottom: horns, dry → 伴
There’s also something like o(mouth, mouth) for outside-inside: mouth, mouth → 回
I mean, seeing this, we probably both realize it’s too much of a hassle for people on WK to ask for help. Though if you still really want to, you could do this data with the WK elements, and I’ll translate to RTK. But I’m not sure if that would speed up the process too much, so please don’t overdo it initially
I can do it directly with the RTK names, when I have the kanji in front of me it’s really not hard to see which RTK name is which radical. I requested edit access.
Sidenote, until I saw the spreadsheet I had no idea you could search for kanji using the same radical twice or three times by just appending a number like “mouth3” for product, that’s neat
Interestingly some of the RTK decompositions of kanji into radicals seem to differ from the Wanikani ones. For example 百 is decomposed into one/ceiling + white by RTK and into leaf + sun by Wanikani. Which is presumably why searching for leaf sun does not find it.